可观测性
AI Service 可观测性
AI Service observability 是一项实验性功能。它的 API 和行为在未来版本中可能会发生变化。
AI Service 的 observability 机制允许用户追踪一次 AiService 调用期间到底发生了什么。
一次调用内部可能会包含多次 LLM 调用,而这些调用中的任意一次都可能成功,也可能失败。
AI Service observability 允许你跟踪完整的调用链路及其结果。
AI Service observability 能力仅在使用 AI Services 时可用。
它属于更高层的抽象,不能直接应用于 ChatModel 或 StreamingChatModel。
该实现最初来自 Quarkus LangChain4j extension, 后续被移植回了这里。
事件类型
每一种事件类型都有唯一标识符,
可以用来在多次调用之间做事件关联。
每种事件类型都包含封装在
InvocationContext
中的信息。
当前支持以下事件类型:
| Event Name | Description |
|---|---|
AiServiceStartedEvent | 当一次 LLM 调用开始时触发。 |
AiServiceRequestIssuedEvent | 在向 LLM 发送请求之前立即触发。它包含本次请求的详细信息。需要注意的是,当存在 tools 或 guardrails 时,在一次 AiService 调用期间它可能会被触发多次。 其中包含 system message、user message 等信息。 |
AiServiceResponseReceivedEvent | 当收到来自 LLM 的响应时触发。它包含 LLM 响应以及对应的请求。需要注意的是,当存在 tools 或 guardrails 时,在一次 AiService 调用期间它可能会被触发多次。 其中包含 system message、user message 等信息。 并不是每次调用都会收到这个事件。如果调用失败,则会收到 AiServiceErrorEvent 作为替代。 |
AiServiceErrorEvent | 当一次 LLM 调用失败时触发。失败原因可能是网络故障、AiService 不可用、输入 / 输出 guardrail 阻止了请求,或者其他很多情况。 它会包含本次失败的相关信息。 |
AiServiceCompletedEvent | 当一次 LLM 调用成功完成时触发。 并不是每次调用都会收到这个事件。如果调用失败,则会收到 AiServiceErrorEvent 作为替代。它会包含本次调用结果的相关信息。 |
ToolExecutedEvent | 当一次工具调用完成时触发。需要注意的是,在一次单独的 LLM 调用中,它可能被触发多次。 其中包含工具请求与执行结果的信息。 |
InputGuardrailExecutedEvent | 当input guardrail 校验完成后触发。每执行一次 guardrail,就会触发一个对应事件。 它包含某个输入 guardrail 的输入、输出(例如成功还是失败)以及执行耗时等信息。 |
OutputGuardrailExecutedEvent | 当output guardrail 校验完成后触发。每执行一次 guardrail,就会触发一个对应事件。 它包含某个输出 guardrail 的输入、输出(例如成功?失败?重试?reprompt?)以及执行耗时等信息。 |
监听事件
每一种事件类型 都有各自的 listener, 你可以实现对应的 listener 来接收该事件。 你可以按需选择想监听的事件种类。
要监听某类事件,只需创建一个实现了对应 listener 接口的类即可。 可用的 listener 接口如下:
定义好 listener 之后,需要在创建 AI Services 时注册它们。
AiServices 类
上提供了多种 registerListener 方法重载可供使用。
例如,下面这段代码展示了如何创建并注册一个监听 AiServiceCompletedEvent 的 listener:
import java.time.Instant;
import java.util.List;
import java.util.Optional;
import java.util.UUID;
import dev.langchain4j.observability.api.AiServiceListenerRegistrar;
import dev.langchain4j.observability.api.event.AiServiceCompletedEvent;
import dev.langchain4j.observability.api.listener.AiServiceCompletedListener;
import dev.langchain4j.invocation.InvocationContext;
public class MyAiServiceCompletedListener implements AiServiceCompletedListener {
@Override
public void onEvent(AiServiceCompletedEvent event) {
InvocationContext invocationContext = event.invocationContext();
Optional<Object> result = event.result();
// 同一次 LLM 调用相关的所有事件,其 invocationId 都是相同的
UUID invocationId = invocationContext.invocationId();
String aiServiceInterfaceName = invocationContext.interfaceName();
String aiServiceMethodName = invocationContext.methodName();
List<Object> aiServiceMethodArgs = invocationContext.methodArguments();
Object chatMemoryId = invocationContext.chatMemoryId();
Instant eventTimestamp = invocationContext.timestamp();
// 在这里处理这些数据
}
}
// 创建 AI Service 时
MyAiServiceCompletedListener myListener = new MyAiServiceCompletedListener();
var myService = AiServices.builder(MyAiService.class)
.chatModel(chatModel) // 也可以是 .streamingChatModel(...)
.registerListener(myListener)
.build();
创建你自己的事件和监听器
AI Service observability 能力本身就是为可扩展性而设计的。
如果你想创建自己的事件,可以通过实现
AiServiceEvent
接口来定义自定义事件。
然后,再通过实现
AiServiceListener
接口,创建自定义的事件 listener。
定义好事件和 listener 之后,你还需要通过获取 / 管理 AiServiceListenerRegistrar 实例,
并调用 fireEvent(event) 方法,来真正触发该事件。
一旦事件会被触发,你就可以像使用内置事件一样,为它创建 listener 并完成注册。
扩展点
你也可以通过实现
AiServiceListenerRegistrarFactory
并通过 Java Service Provider Interface(Java SPI) 注册它,
来创建自定义的
AiServiceListenerRegistrar。
如果你希望自定义 listener 的注册 / 取消注册方式, 以及事件的触发方式,这会很有帮助。
Chat Model 可观测性
某些 ChatModel 和 StreamingChatModel 的实现
(见 “Observability” 一列)
支持配置 ChatModelListener 来监听以下事件:
- 发往 LLM 的请求
- 来自 LLM 的响应
- 错误
这些事件会包含多种属性,详见 OpenTelemetry Generative AI Semantic Conventions,例如:
- 请求:
- Messages
- Model
- Temperature
- Top P
- Max Tokens
- Tools
- Response Format
- 等等
- �响应:
- Assistant Message
- ID
- Model
- Token Usage
- Finish Reason
- 等等
下面是使用 ChatModelListener 的示例:
ChatModelListener listener = new ChatModelListener() {
@Override
public void onRequest(ChatModelRequestContext requestContext) {
ChatRequest chatRequest = requestContext.chatRequest();
List<ChatMessage> messages = chatRequest.messages();
System.out.println(messages);
ChatRequestParameters parameters = chatRequest.parameters();
System.out.println(parameters.modelName());
System.out.println(parameters.temperature());
System.out.println(parameters.topP());
System.out.println(parameters.topK());
System.out.println(parameters.frequencyPenalty());
System.out.println(parameters.presencePenalty());
System.out.println(parameters.maxOutputTokens());
System.out.println(parameters.stopSequences());
System.out.println(parameters.toolSpecifications());
System.out.println(parameters.toolChoice());
System.out.println(parameters.responseFormat());
if (parameters instanceof OpenAiChatRequestParameters openAiParameters) {
System.out.println(openAiParameters.maxCompletionTokens());
System.out.println(openAiParameters.logitBias());
System.out.println(openAiParameters.parallelToolCalls());
System.out.println(openAiParameters.seed());
System.out.println(openAiParameters.user());
System.out.println(openAiParameters.store());
System.out.println(openAiParameters.metadata());
System.out.println(openAiParameters.serviceTier());
System.out.println(openAiParameters.reasoningEffort());
}
System.out.println(requestContext.modelProvider());
Map<Object, Object> attributes = requestContext.attributes();
attributes.put("my-attribute", "my-value");
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
ChatResponse chatResponse = responseContext.chatResponse();
AiMessage aiMessage = chatResponse.aiMessage();
System.out.println(aiMessage);
ChatResponseMetadata metadata = chatResponse.metadata();
System.out.println(metadata.id());
System.out.println(metadata.modelName());
System.out.println(metadata.finishReason());
if (metadata instanceof OpenAiChatResponseMetadata openAiMetadata) {
System.out.println(openAiMetadata.created());
System.out.println(openAiMetadata.serviceTier());
System.out.println(openAiMetadata.systemFingerprint());
}
TokenUsage tokenUsage = metadata.tokenUsage();
System.out.println(tokenUsage.inputTokenCount());
System.out.println(tokenUsage.outputTokenCount());
System.out.println(tokenUsage.totalTokenCount());
if (tokenUsage instanceof OpenAiTokenUsage openAiTokenUsage) {
System.out.println(openAiTokenUsage.inputTokensDetails().cachedTokens());
System.out.println(openAiTokenUsage.outputTokensDetails().reasoningTokens());
}
ChatRequest chatRequest = responseContext.chatRequest();
System.out.println(chatRequest);
System.out.println(responseContext.modelProvider());
Map<Object, Object> attributes = responseContext.attributes();
System.out.println(attributes.get("my-attribute"));
}
@Override
public void onError(ChatModelErrorContext errorContext) {
Throwable error = errorContext.error();
error.printStackTrace();
ChatRequest chatRequest = errorContext.chatRequest();
System.out.println(chatRequest);
System.out.println(errorContext.modelProvider());
Map<Object, Object> attributes = errorContext.attributes();
System.out.println(attributes.get("my-attribute"));
}
};
ChatModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.listeners(List.of(listener))
.build();
model.chat("Tell me a joke about Java");
attributes map 允许你在同一个 ChatModelListener 的 onRequest、onResponse 和 onError
之间传递信息,也允许在多个 ChatModelListener 之间共享信息。
如果你需要向 listener 提供“按次调用”的元数据,
可以使用 ChatRequestOptions。
例如,你可以通过 listenerAttributes,
把租户 ID 或关联 ID 传给 ChatModelListener。
这些选项只在 LangChain4j 的调用链内部使用,
并不会发送给 LLM 提供商。
ChatRequest chatRequest = ChatRequest.builder()
.messages(UserMessage.from("Tell me a joke about Java"))
.build();
ChatRequestOptions options = ChatRequestOptions.builder()
.addListenerAttribute("tenantId", "tenant-123")
.addListenerAttribute("correlationId", "corr-456")
.build();
model.chat(chatRequest, options);
同样的方式也适用于 StreamingChatModel.chat(chatRequest, options, handler)。
监听器的工作方式
- listeners 以
List<ChatModelListener>形式指定,并按迭代顺序依次调用。 - listeners 会同步执行,并运行在同一线程中。关于 streaming 情况的额外说明见下文。 第二个 listener 必须等第一个 listener 返回后才会被调用。
ChatModelListener.onRequest()会在调用 LLM 提供商 API 之前立即执行。ChatModelListener.onRequest()对于每个请求只会调用一次。 如果调用 LLM 提供商 API 时出错并发生重试,ChatModelListener.onRequest()不会在每次重试时都重新调用。ChatModelListener.onResponse()只会调用一次, 即在成功收到 LLM 提供商响应后立即调用。ChatModelListener.onError()也只会调用一次。 如果调用 LLM 提供商 API 时出错并发生重试,ChatModelListener.onError()不会在每次重试时都重新调用。- 如果某个
ChatModelListener方法抛出异常, 异常会以WARN级别记录日志,后续 listener 仍会继续正常执行。 - 通过
ChatModelRequestContext、ChatModelResponseContext和ChatModelErrorContext提供的ChatRequest, 是最终请求对象,其中已经将配置在ChatModel上的默认ChatRequestParameters与按次请求指定的ChatRequestParameters合并完成。 - 对于
StreamingChatModel,ChatModelListener.onResponse()和ChatModelListener.onError()所在线程,与ChatModelListener.onRequest()所在线程不同。 当前线程上下文不会自动传播, 因此如果你需要从ChatModelListener.onRequest()把数据带到ChatModelListener.onResponse()或ChatModelListener.onError(), 可以使用attributesmap。 - 对于
StreamingChatModel,ChatModelListener.onResponse()会在StreamingChatResponseHandler.onCompleteResponse()之前调用;ChatModelListener.onError()则会在StreamingChatResponseHandler.onError()之前调用。
Moderation Model 可观测性
支持 listeners 的 ModerationModel 实现
(例如 OpenAiModerationModel、MistralAiModerationModel 和 WatsonxModerationModel)
允许你配置 ModerationModelListener 来监听以下事件:
- 发往 moderation API 的请求
- 来自 moderation API 的响应
- 错误
下面是使用 ModerationModelListener 的示例:
ModerationModelListener listener = new ModerationModelListener() {
@Override
public void onRequest(ModerationModelRequestContext requestContext) {
ModerationRequest moderationRequest = requestContext.moderationRequest();
// 访问正在接受审核的文本
System.out.println("Moderating texts: " + moderationRequest.texts());
System.out.println(requestContext.modelProvider());
System.out.println(moderationRequest.modelName());
Map<Object, Object> attributes = requestContext.attributes();
attributes.put("startTime", System.currentTimeMillis());
}
@Override
public void onResponse(ModerationModelResponseContext responseContext) {
ModerationResponse moderationResponse = responseContext.moderationResponse();
Moderation moderation = moderationResponse.moderation();
System.out.println("Flagged: " + moderation.flagged());
if (moderation.flagged()) {
System.out.println("Flagged text: " + moderation.flaggedText());
}
ModerationRequest moderationRequest = responseContext.moderationRequest();
System.out.println(moderationRequest);
System.out.println(responseContext.modelProvider());
System.out.println(moderationRequest.modelName());
Map<Object, Object> attributes = responseContext.attributes();
Long startTime = (Long) attributes.get("startTime");
if (startTime != null) {
System.out.println("Duration: " + (System.currentTimeMillis() - startTime) + "ms");
}
}
@Override
public void onError(ModerationModelErrorContext errorContext) {
Throwable error = errorContext.error();
error.printStackTrace();
ModerationRequest moderationRequest = errorContext.moderationRequest();
System.out.println(moderationRequest);
System.out.println(errorContext.modelProvider());
System.out.println(moderationRequest.modelName());
Map<Object, Object> attributes = errorContext.attributes();
System.out.println(attributes.get("startTime"));
}
};
ModerationModel model = OpenAiModerationModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.listeners(List.of(listener))
.build();
model.moderate("Text to check for policy violations");
attributes map 允许你在同一个 ModerationModelListener 的 onRequest、onResponse 和 onError
之间传递信息,也允许多个 ModerationModelListener 之间共享信息。
监听器的工作方式
- listeners 以
List<ModerationModelListener>形式指定,并按迭代顺序依次调用。 - listeners 会同步执行,并运行在同一线程中。
ModerationModelListener.onRequest()会在调用 moderation API 之前立即执行。ModerationModelListener.onRequest()对每个请求只会调用一次。 如果调用 moderation API 时出错并发生重试,ModerationModelListener.onRequest()不会在每次重试时都被调用。ModerationModelListener.onResponse()只会调用一次, 即在成功收到响应后立即调用。ModerationModelListener.onError()也只会调用一次。 如果调用 moderation API 时出错并发生重试,ModerationModelListener.onError()不会在每次重试时都被调用。- 如果某个
ModerationModelListener方法抛出异常, 异常会以WARN级别记录日志,后续 listener 仍会继续正常执行。
RAG 可观测性(EmbeddingModel、EmbeddingStore 和 ContentRetriever)
EmbeddingModel、EmbeddingStore 和 ContentRetriever
都可以通过 listener 做观测与埋点,用于观察:
- 延迟(可通过
attributes记录开始时间并计算耗时) - 载荷内容(例如
EmbeddingSearchRequest.queryEmbedding()以及检索到的匹配结果 / 内容) - 错误
EmbeddingModel 监听器
实现 EmbeddingModelListener:
import dev.langchain4j.model.embedding.listener.EmbeddingModelListener;
import dev.langchain4j.model.embedding.listener.EmbeddingModelRequestContext;
import dev.langchain4j.model.embedding.listener.EmbeddingModelResponseContext;
import dev.langchain4j.model.embedding.listener.EmbeddingModelErrorContext;
public class MyEmbeddingModelListener implements EmbeddingModelListener {
@Override
public void onRequest(EmbeddingModelRequestContext requestContext) {
requestContext.attributes().put("startNanos", System.nanoTime());
}
@Override
public void onResponse(EmbeddingModelResponseContext responseContext) {
long startNanos = (long) responseContext.attributes().get("startNanos");
long durationNanos = System.nanoTime() - startNanos;
// 在这里处理耗时和 / 或 responseContext.response()
}
@Override
public void onError(EmbeddingModelErrorContext errorContext) {
// 在这里处理 errorContext.error()
}
}
通过 EmbeddingModel#addListener(s) 挂载 listener:
EmbeddingModel observedModel = embeddingModel.addListener(new MyEmbeddingModelListener());
observedModel.embed("hello");
EmbeddingStore 监听器
实现 EmbeddingStoreListener:
import dev.langchain4j.store.embedding.listener.EmbeddingStoreListener;
import dev.langchain4j.store.embedding.listener.EmbeddingStoreRequestContext;
import dev.langchain4j.store.embedding.listener.EmbeddingStoreResponseContext;
import dev.langchain4j.store.embedding.listener.EmbeddingStoreErrorContext;
public class MyEmbeddingStoreListener implements EmbeddingStoreListener {
@Override
public void onRequest(EmbeddingStoreRequestContext<?> requestContext) {
requestContext.attributes().put("startNanos", System.nanoTime());
}
@Override
public void onResponse(EmbeddingStoreResponseContext<?> responseContext) {
long startNanos = (long) responseContext.attributes().get("startNanos");
long durationNanos = System.nanoTime() - startNanos;
// 在这里处理耗时和 / 或响应载荷(如果有),例如:
if (responseContext instanceof EmbeddingStoreResponseContext.Search<?> search) {
// 在这里处理 search.searchResult()
}
}
@Override
public void onError(EmbeddingStoreErrorContext<?> errorContext) {
// 在这里处理 errorContext.error()
}
}
通过 EmbeddingStore#addListener(s) 挂载 listener:
EmbeddingStore<TextSegment> observedStore = embeddingStore.addListener(new MyEmbeddingStoreListener());
// 后续像平常一样使用 observedStore,例如在 EmbeddingStoreIngestor / EmbeddingStoreContentRetriever 中使用
ContentRetriever 监听器
实现 ContentRetrieverListener:
import dev.langchain4j.rag.content.retriever.listener.ContentRetrieverListener;
import dev.langchain4j.rag.content.retriever.listener.ContentRetrieverRequestContext;
import dev.langchain4j.rag.content.retriever.listener.ContentRetrieverResponseContext;
import dev.langchain4j.rag.content.retriever.listener.ContentRetrieverErrorContext;
public class MyContentRetrieverListener implements ContentRetrieverListener {
@Override
public void onRequest(ContentRetrieverRequestContext requestContext) {
requestContext.attributes().put("startNanos", System.nanoTime());
}
@Override
public void onResponse(ContentRetrieverResponseContext responseContext) {
long startNanos = (long) responseContext.attributes().get("startNanos");
long durationNanos = System.nanoTime() - startNanos;
// 在这里处理耗时和 / 或 responseContext.contents()
}
@Override
public void onError(ContentRetrieverErrorContext errorContext) {
// 在这里处理 errorContext.error()
}
}
通过 ContentRetriever#addListener(s) 挂载 listener:
ContentRetriever observedRetriever = contentRetriever.addListener(new MyContentRetrieverListener());
observedRetriever.retrieve(Query.from("my query"));
监听器的工作方式
- listeners 以
List形式指定,并按迭代顺序依次调用。 - listeners 会同步执行,并运行在同一线程中。
onRequest()会在执行底层操作之前立即调用。onResponse()会在底层操作成功完成后调用一次。onError()会在底层操作抛出异常时调用一次。- 如果某个 listener 方法抛出异常,
异常会以
WARN级别记录日志,并被忽略。 attributesmap 允许你在同一个 listener 的onRequest、onResponse和onError之间传递信息,也允许多个 listener 之间共享信息。
使用 Micrometer 的可观测性指标
langchain4j-micrometer-metrics 模块为 LangChain4j 提供了基于 Micrometer 的 metrics 实现。
当前它通过一个 ChatModelListener 实现,为 ChatModel 和 StreamingChatModel
的交互采集指标,并将数据写入 Micrometer 的 MeterRegistry。
这些指标的命名遵循 OpenTelemetry Semantic Conventions for Generative AI Metrics (v1.39.0)。
⚠️ Experimental: 该模块被标记为
@Experimental,未来版本中可能出现破坏性变更。
⚠️ Warning: OpenTelemetry 的 Generative AI Semantic Conventions 目前仍是实验性且不稳定的。 这意味着它们在未来可能会有破坏性变更。 如果你基于这些 convention 搭建了 dashboard、告警和自动化流程, 那么在 convention 更新时,你很可能也需要做对应的破坏性调整。
指标
当前会采集以下指标:
| Metric Name | Type | Description |
|---|---|---|
gen_ai.client.token.usage | Histogram (DistributionSummary) | 每次 chat 模型请求所使用的输入和输出 token 数量 |
gen_ai.client.token.usage 上的 tags
| Tag | Description | Example Values |
|---|---|---|
gen_ai.operation.name | 正在执行的操作 | chat |
gen_ai.provider.name | AI provider 名称 | openai, azure.ai.inference, anthropic |
gen_ai.request.model | 请求中的模型名 | gpt-4, gpt-35-turbo |
gen_ai.response.model | 响应中的模型名 | gpt-4-0613 |
gen_ai.token.type | 统计的是哪类 token | input, output |
创建 MicrometerMetricsChatModelListener
MicrometerMetricsChatModelListener 负责采集 ChatModel 和 StreamingChatModel
交互中的指标。
它在实例化时需要一个 Micrometer 的 MeterRegistry。
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.micrometer.metrics.listeners.MicrometerMetricsChatModelListener;
import dev.langchain4j.model.azure.AzureOpenAiChatModel;
import dev.langchain4j.model.chat.request.ChatRequest;
import dev.langchain4j.model.chat.response.ChatResponse;
import io.micrometer.core.instrument.MeterRegistry;
import java.util.List;
// 获取 MeterRegistry
MeterRegistry meterRegistry = new SimpleMeterRegistry();
// 1. 使用 MeterRegistry 创建 listener
MicrometerMetricsChatModelListener listener =
new MicrometerMetricsChatModelListener(meterRegistry);
// 2. 把 listener 加到你的 ChatModel 上
AzureOpenAiChatModel chatModel = AzureOpenAiChatModel.builder()
.endpoint(System.getenv("AZURE_OPENAI_ENDPOINT"))
.apiKey(System.getenv("AZURE_OPENAI_KEY"))
.deploymentName(System.getenv("AZURE_OPENAI_DEPLOYMENT_NAME"))
.listeners(List.of(listener))
.build();
// 3. 像平常一样使用 chat model,指标会自动采集
ChatResponse response = chatModel.chat(ChatRequest.builder()
.messages(UserMessage.from("Hello!"))
.build());
Micrometer 观测 API
这里通过 Micrometer Observation API
实现了 ChatModelListener,
从而能够透明地产生 Metrics 和 Traces。
该实现位于 langchain4j-observation 模块中。
产生的遥测数据
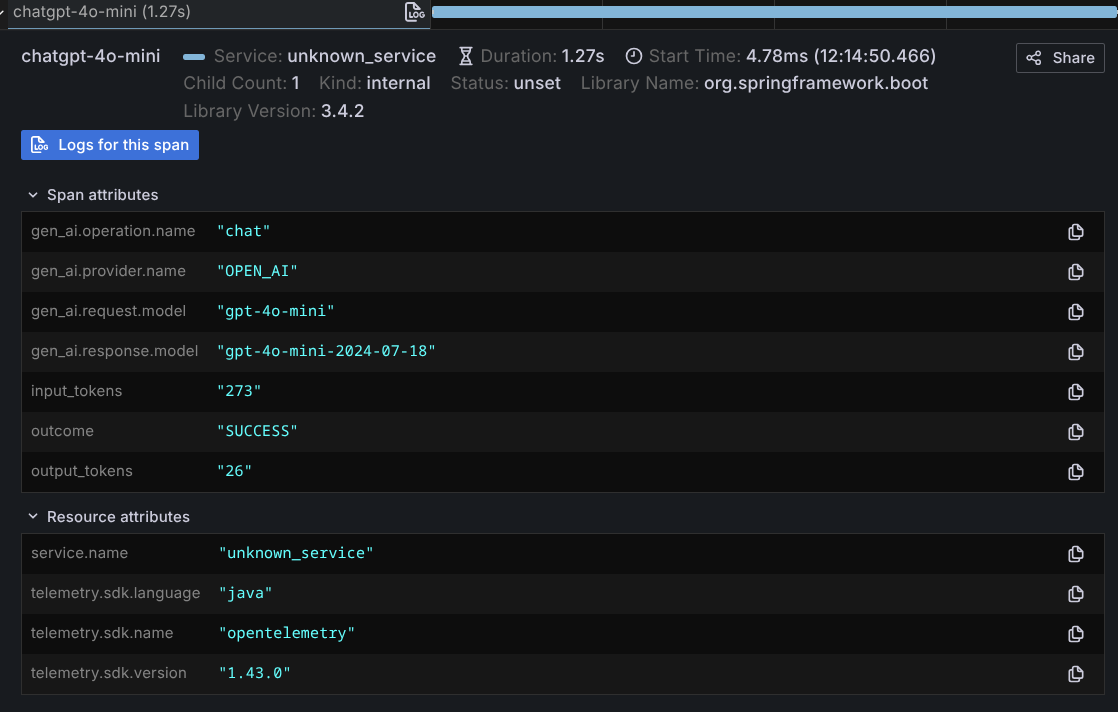
追踪
它会为每次 chat 交互生成 span。
示例:
指标
会生成以下 histogram:
- gen_ai_client_token_usage
- gen_ai_client_operation_duration
示例:
# HELP gen_ai_client_operation_duration_active_seconds
# TYPE gen_ai_client_operation_duration_active_seconds summary
gen_ai_client_operation_duration_active_seconds_count{gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="unknown",outcome="SUCCESS"} 0
gen_ai_client_operation_duration_active_seconds_sum{gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="unknown",outcome="SUCCESS"} 0.0
# HELP gen_ai_client_operation_duration_active_seconds_max
# TYPE gen_ai_client_operation_duration_active_seconds_max gauge
gen_ai_client_operation_duration_active_seconds_max{gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="unknown",outcome="SUCCESS"} 0.0
# HELP gen_ai_client_operation_duration_seconds
# TYPE gen_ai_client_operation_duration_seconds summary
gen_ai_client_operation_duration_seconds_count{error="none",gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="gpt-4o-mini-2024-07-18",outcome="SUCCESS"} 2
gen_ai_client_operation_duration_seconds_sum{error="none",gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="gpt-4o-mini-2024-07-18",outcome="SUCCESS"} 3.384050045
# HELP gen_ai_client_operation_duration_seconds_max
# TYPE gen_ai_client_operation_duration_seconds_max gauge
gen_ai_client_operation_duration_seconds_max{error="none",gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="gpt-4o-mini-2024-07-18",outcome="SUCCESS"} 2.115592691
# HELP gen_ai_client_token_usage_tokens Measures the quantity of used tokens
# TYPE gen_ai_client_token_usage_tokens summary
gen_ai_client_token_usage_tokens_count{gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="gpt-4o-mini-2024-07-18",gen_ai_token_type="input"} 2
gen_ai_client_token_usage_tokens_sum{gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="gpt-4o-mini-2024-07-18",gen_ai_token_type="input"} 508.0
gen_ai_client_token_usage_tokens_count{gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="gpt-4o-mini-2024-07-18",gen_ai_token_type="output"} 2
gen_ai_client_token_usage_tokens_sum{gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="gpt-4o-mini-2024-07-18",gen_ai_token_type="output"} 53.0
# HELP gen_ai_client_token_usage_tokens_max Measures the quantity of used tokens
# TYPE gen_ai_client_token_usage_tokens_max gauge
gen_ai_client_token_usage_tokens_max{gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="gpt-4o-mini-2024-07-18",gen_ai_token_type="input"} 273.0
gen_ai_client_token_usage_tokens_max{gen_ai_operation_name="chat",gen_ai_provider_name="OPEN_AI",gen_ai_request_model="gpt-4o-mini",gen_ai_response_model="gpt-4o-mini-2024-07-18",gen_ai_token_type="output"} 27.0
Spring Boot 应用中的可观测性
更多细节见这里。
关于如何在 Spring Boot 应用中采集 Micrometer Metrics 的更多说明见这里。
关于如何将 Micrometer Observation API 库集成到 Spring Boot 中, 可参见这里。
第三方集成
OpenTelemetry GenAI 插桩
由社区维护的 otel-genai-bridges 项目提供了一个 Spring Boot starter, 可以基于 OpenTelemetry Generative AI semantic conventions 自动为 LangChain4j chat 应用注入遥测能力。
为什么使用它?
- 自动包装任意
ChatModelBean,并产出 spans、events 和 metrics。 - 开箱即用地捕获 prompts、completions、tool calls、延迟、token 使用量、成本,以及 RAG 检索延迟。
- 提供 Docker Compose 示例(Collector → Tempo/Prometheus → Grafana),并附带预制的 Grafana dashboard。
快速开始
将 starter 加入你的 Spring Boot 项目:
<!-- pom.xml -->
<dependency>
<groupId>com.dineshkumarkummara.otel</groupId>
<artifactId>langchain4j-otel</artifactId>
<version>0.1.0-SNAPSHOT</version>
</dependency>
在 application.yaml 中启用 starter:
otel:
langchain4j:
enabled: true
system: openai
default-model: gpt-4o
capture-prompts: true
capture-completions: true
cost:
enabled: true
input-per-thousand: 0.0005
output-per-thousand: 0.0015
其中嵌套的 cost 配置块是可选的;
当你希望采集按 token 计费的相关指标时再加上即可。
当 starter 依赖出现在 classpath 上后,
它会自动发现 ChatModel Bean,并为其包裹上 telemetry 能力。
Observability 视图

如果你想查看一个完整可运行示例 (包括整套 observability stack 以及与 Semantic Kernel 的能力对齐), 请参考 dineshkumarkummara/otel-genai-bridges。